Was ist der Elastic Stack?
Der Elastic Stack (früher ELK Stack) ist die Bezeichnung für eine Sammlung von Open Source Anwendungen, die sich in den letzten Jahren immer größerer Beliebtheit erfreuen. ELK steht dabei für Elasticsearch, Logstash und Kibana. Der Hauptzweck ist das Sammeln, Aufbereiten und Visualisieren von beliebigen Daten für verschiedenste Analysen.
Dies ist der erste Teil einer Artikelreihe, die als Leitfaden für Einsteiger dienen soll. Diesmal geht es darum, einen Überblick über den Elastic Stack als Ganzes und seine verschiedenen Komponenten zu erlangen. In den folgenden Blogbeiträgen gehen wir auf die einzelnen Anwendungen ein und beschreiben beispielhaft die Installation und Konfiguration.
Die Rolle des Elastic Stacks in der Cybersecurity
Der Elastic Stack spielt eine zentrale Rolle in der Cybersecurity aufgrund seiner vielfältigen Fähigkeiten:
-
Log-Analyse: Der Elastic Stack ermöglicht die zentrale Sammlung und Analyse von Log-Daten aus verschiedenen Quellen, einschließlich Sicherheitsprotokollen. Dies ermöglicht es Sicherheitsteams, verdächtige Aktivitäten zu erkennen und zu überwachen.
-
Echtzeitüberwachung: Mit Kibana, einer Komponente des Elastic Stacks, können Sicherheitsteams Echtzeit-Dashboards erstellen, um den Netzwerkverkehr und andere sicherheitsrelevante Aktivitäten zu überwachen. Dadurch können sie Angriffe in Echtzeit erkennen und darauf reagieren.
-
Forensische Analyse: Der Elastic Stack bietet umfangreiche Möglichkeiten zur forensischen Analyse von Sicherheitsvorfällen. Durch die Suche und Analyse von Log-Daten können Sicherheitsexperten den Ursprung und den Umfang von Angriffen ermitteln, um geeignete Gegenmaßnahmen zu ergreifen.
-
Sicherheitsalarme: Bei der Überwachung von Systemen kann der Elastic Stack Sicherheitsalarme regelbasiert erzeugen, indem er verdächtige Aktivitäten automatisch erkennt. Durch die Integration von Machine Learning können außerdem bisher unbekannte Bedrohungen identifiziert werden.
Bei Yekta IT setzen wir den Elastic Stack bei unseren Kunden ein, bspw. um Firmeninfrastruktur und Server zu überwachen und verdächtige Aktivitäten zu erkennen. Der Elastic Stack ist dabei die zentrale Komponente eines sogenannten Security Information and Event Management Systems (SIEM). Daher verfügen wir über umfangreiche Erfahrung im Umgang mit den verschiedenen Komponenten des Elastic Stack. Dieses Wissen wollen wir teilen, um den Einstieg in die Welt von Elastic leichter zu machen.
Neben der IT-Sicherheit kann der Elastic Stack auch für andere Zwecke eingesetzt werden:
-
Auswertung und Visualisierung von Umsätzen und Lagerbeständen eines Online-Shops
-
Darstellung von Unternehmenskennzahlen wie Umsatz, Kosten, Gewinn, Marketingdaten, Webseitenbesucher usw.
Die wichtigsten Fakten zum Elastic Stack
-
wird von der Firma Elastic NV entwickelt
-
zwei Hostingmöglichkeiten:
-
self hosted auf dem eigenen Server
-
in der Elastic Cloud als Software as a Service Modell (SaaS)
-
-
Link zur Demo zum einfachen Ausprobieren
-
Elastic folgte bis 2018 dem “Open Core” Modell, bei dem Elasticsearch und Kibana unter der Apache 2.0 Lizenz standen und somit frei nutzbar waren. Andere Teile standen unter der kommerziellen Elastic License
-
2021 ersetzte Elastic jedoch die Apache 2.0 Lizenz durch ihre eigene Server Side Public License, die den Einsatz in Cloudangeboten verbietet
-
dies zielte vermutlich auf Amazon AWS ab, die Elasticsearch-Services in ihrer Cloud anboten und dafür aufgrund der Apache Lizenz keine Lizenzgebühren an Elastic zahlen mussten (Link zum Blogpost des Elastic CEOs)
-
seitdem darf Elasticsearch und Kibana nur noch in der offiziellen Elastic Cloud angeboten werden (self hosted Umgebungen sind davon aber nicht betroffen)
-
-
daraufhin wurden Elasticsearch und Kibana geforked und werden seitdem unter dem Projekt “OpenSearch” mit Apache 2.0 Lizenz weiterentwickelt
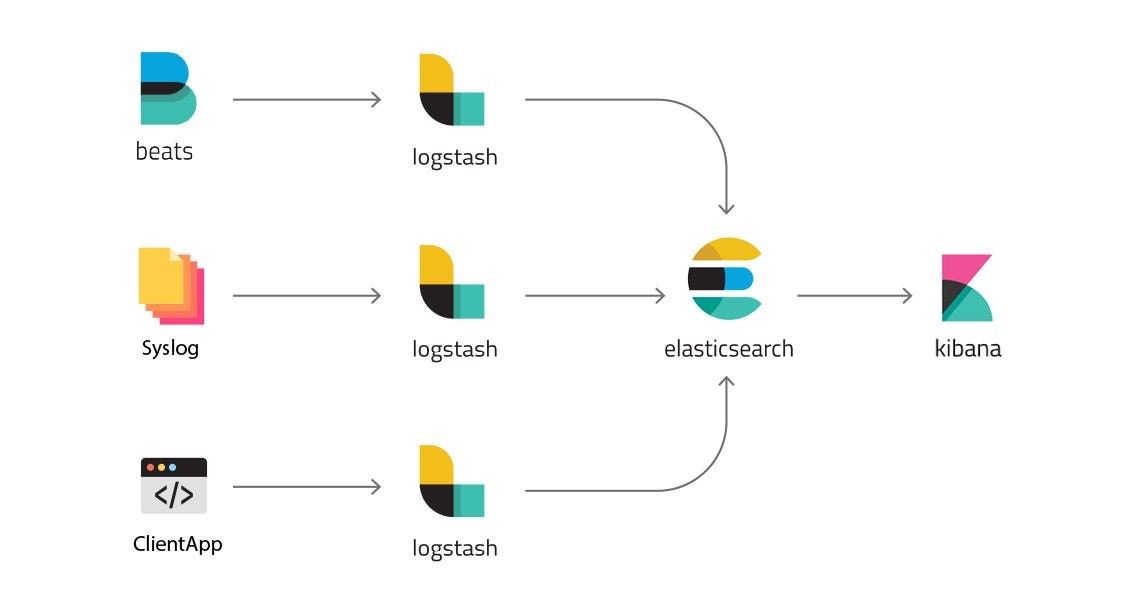
Elasticsearch - die zentrale Komponente
Elasticsearch ist die zentrale Komponente des Elastic Stack. Dabei handelt es sich um einen Suchserver auf Basis von Apache Lucene, der beliebige Daten über ein REST-API entgegennimmt und im NoSQL-Format speichert. Anschließend werden die Daten indiziert, damit sie durchsuchbar sind. Ein Index entspricht dabei im übertragenen Sinne einer SQL-Tabelle. Ein Eintrag in einem Index wird als Dokument bezeichnet, dies entspricht quasi einer Zeile in einer SQL-Tabelle. Im Gegensatz zu SQL gibt es bei NoSQL aber keine starren Tabellenschemata, sodass die Datenstruktur nicht im Vorfeld bekannt sein muss und sich dynamisch erweitern lässt.
Um die Skalierbarkeit und Ausfallsicherheit zu verbessern, zerteilt Elasticsearch auf Wunsch jeden Index in Bruchstücke, die sogenannten Shards. Die Shards können dann auf verschiedene Elasticsearch-Server, auch Nodes genannt, aufgeteilt werden. Eine Gruppe von Nodes heißt Cluster.
Elasticsearch ist als verteiltes System konzipiert, denn die Nodes koordinieren sich untereinander und wählen einen Node zum Master. Dieser steuert dann das gesamte Cluster. Beim Ausfall einzelner Nodes funktioniert das Cluster weiterhin, da sämtliche Daten stets redundant vorhanden sind. Fällt der Master aus, übernimmt ein anderer Node nach einer neuen Abstimmung diese Rolle. Diese Eigenschaften machen Elasticsearch besonders resilient gegen Ausfälle und sorgen für eine hohe Skalierbarkeit, sodass riesige Datenmengen verarbeitet werden können. Ein solches verteiltes System erhöht jedoch besonders am Anfang die Komplexität enorm und erschwert die Fehlersuche. Daher empfehlen wir Einsteigern, zunächst mit einem einzelnen Node zu starten.
Logstash - der Datenaufbereiter
Die Daten kommen oft aus einer Vielzahl von Quellen, z.B. von verschiedenen Servern eines Unternehmens. Daher ist ein Tool nötig, welches die Daten aufbereitet und filtert. Das ist die Aufgabe von Logstash, das entweder als Anwendung auf einem zu überwachenden Server läuft, oder auf einem separaten Server läuft und die Daten von einem der Beats erhält (siehe unten). In der Logstash-Konfiguration lässt sich einstellen, aus welchen Quellen die Daten stammen und wohin sie gesendet werden.
Die Logstash Pipeline besteht aus drei Schritten:
-
Input
-
Filter
-
Output
Input
Logstash besitzt eine Reihe von Input-Plugins, die Daten aus verschiedenen Quellen sammeln. Einige Beispiele dafür sind:
-
file: liest Daten aus Dateien
-
http: empfängt Daten via HTTP-Requests
-
syslog: liest Daten aus dem Linux-Systemlog
Filter
Im nächsten Schritt können Filter auf die Rohdaten angewendet werden, um unwichtige Dinge auszuschließen und sie für die weitere Verarbeitung vorzubereiten. Beispiele dafür sind:
-
grok: erzeugt strukturierte Daten aus den Rohdaten. Da z.B. Logdateien zunächst nur unstrukturierte Daten enthalten, können reguläre Ausdrücke angewendet werden, um die Daten zu strukturieren. So würde beispielsweise eine Nginx Logzeile in strukturiertes JSON umgewandelt werden:
-
192.168.1.1 - - [22/Nov/2023:12:34:56 +0000] "GET /example/index.html HTTP/1.1" 200 1234 "http://example.com" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36" -
{ "clientip": "192.168.1.1", "verb": "GET", "uri": "/example/index.html", "protocol": "HTTP/1.1", "response": 200, "bytes": 1234, "referrer": "http://example.com", "useragent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36", "@timestamp": "2023-11-22T12:34:56.000Z" }
-
-
mutate: damit lassen sich Datenfelder umbenennen, ersetzen oder komplett entfernen (z.B. um Datenschutzanforderungen zu erfüllen)
Output
Der wichtigste Output für Logstash ist sicherlich Elasticsearch. Das ist jedoch nicht das einzige Output-Plugin:
-
file: schreibt die Daten in eine Datei
-
http: sendet Daten an einen HTTP-Endpunkt
-
stdout: sendet Daten an den Linux Standard-Output
Logstash kann deutlich mehr als nur Daten an Elasticsearch senden, auch wenn das ein häufiger Anwendungsfall ist.
Kibana - der Visualisierer
Kibana dient zur Visualisierung der gesammelten Daten und ist die browserbasierte Schnittstelle, über die Nutzer mit dem Elastic Stack interagieren. Zentrales Element sind die sogenannten Dashboards, die die Daten anschaulich zusammenfassen. Diese können in einer grafischen Oberfläche selber entwickelt werden, daneben gibt es auch eine Reihe von vorinstallierten Dashboards.
Kibana verfügt über ein rollenbasiertes Berechtigungssystem (RBAC), womit detailliert gesteuert werden kann, welcher Nutzer welche Aktionen auslösen darf und auf welche Menüpunkte er Zugriff hat.
Außerdem dient Kibana als Konfigurations-Oberfläche, über die viele Einstellungen zum Cluster konfiguriert werden können. Daneben stellt Kibana auch ein REST-API zur Verfügung, worüber sich z.B. neue Nutzer und Rollen anlegen lassen (Dokumentation der Kibana-API).
Beats - die Datensammler
Beats sind eine Ergänzung zu Logstash, die entweder unabhängig von Logstash arbeiten oder in Kombination damit. Das folgende Schaubild zeigt den Aufbau eines Elastic Clusters mit Beats:
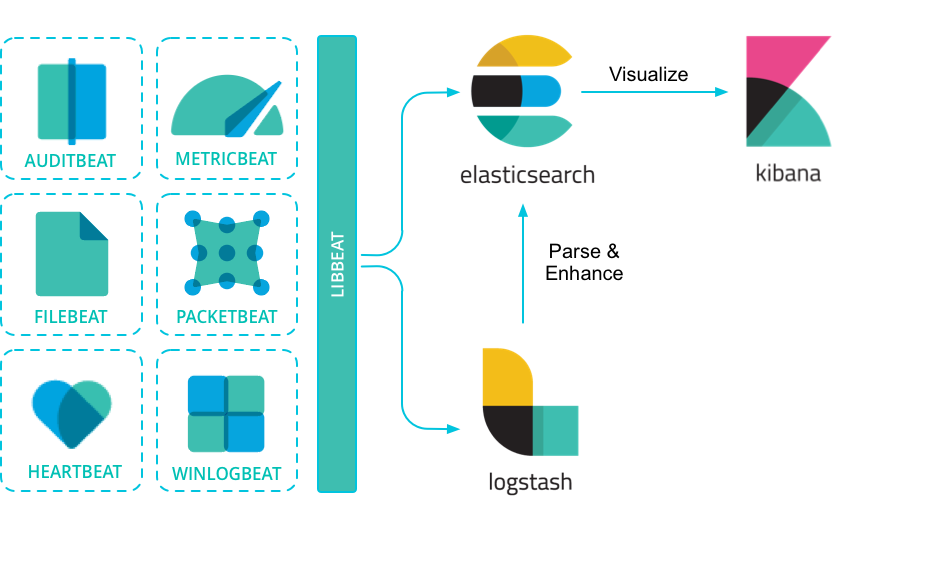
Beats laufen direkt auf den zu überwachenden Servern. Dort sammeln sie alle nötigen Daten und senden diese entweder direkt an Elasticsearch, oder zunächst an Logstash, von wo sie wiederum an Elasticsearch gesendet werden.
Beats wurden entwickelt, um häufig wiederkehrende Probleme zu lösen: so musste man z.B. ohne Metricbeat alle Datenquellen zu CPU und RAM-Auslastung, Speicherbelegung, Netzwerkverkehr usw. manuell in Logstash konfigurieren. Metricbeat übernimmt diese Aufgabe, sodass man nach der Installation lediglich die Zugangsdaten zu Elasticsearch konfigurieren muss. Anschließend sammelt und sendet Metricbeat die Daten automatisch.
Folgende Beats stehen zur Verfügung (Link zur Dokumentation):
-
Auditbeat:
-
überwacht Aktivitäten von Nutzern und Prozessen
-
z.B. Änderungen an kritischen Dateien wie /etc/passwd
-
somit gut geeignet, um potentielle Sicherheitsvorfälle zu entdecken
-
-
Filebeat:
-
überwacht Dateien und Log-Events und sendet diese an Logstash oder Elasticsearch
-
-
Heartbeat:
-
prüft periodisch, ob Services laufen und erreichbar sind
-
erkennt somit z.B. Ausfälle von Webservern
-
verfügbare Methoden sind ICMP (auch bekannt als “Pings”), TCP und HTTP Requests an den entsprechenden Service
-
-
Metricbeat:
-
sammelt Metriken und Statistiken wie CPU-Last, aktive Services, verfügbarer Speicherplatz und vieles mehr
-
-
Packetbeat:
-
sammelt Echtzeit-Netzwerkdaten und Statistiken
-
bietet Einblicke, welche Daten über das Netzwerk gesendet werden
-
unterstützt verschiedene Protokolle wie z.B. HTTP, DNS, NFS usw.
-
-
Winlogbeat:
-
sammelt Windows Event Logs über verschiedene APIs
-
z.B. Anwendungs-Logs, Hardware-Events, System-Events
-
Logs können bereits mit Winlogbeat gefiltert werden und anschließend an Logstash oder Elasticsearch gesendet werden
-
Außerdem gibt es die Möglichkeit, mit dem Libbeat-Framework eigene Beats zu entwickeln. Libbeat stellt die nötigen Schnittstellen für einen Beat zur Verfügung und soll die Entwicklung vereinfachen. Eine Liste verfügbarer Community-Beats findet sich hier.
Elastic Agent & Fleet Server
Der Elastic Agent ist eine alternative Möglichkeit, um Daten auf Servern zu sammeln und an Elasticsearch zu senden. Nach dem all-in-one Prinzip soll er alle Aufgaben übernehmen, die bisher von den einzelnen Beats gelöst wurden. Dazu wird der Elastic Agent auf dem System installiert und anschließend können verschiedene Integrationen aktiviert werden.
Eine Integration ist meist anwendungsspezifisch, so gibt es z.B. eine Nginx-Integration, die automatisch alle relevanten Daten rund um den nginx-Webserver sammelt und an Elasticsearch sendet. Eine Liste verfügbarer Integrationen findet sich in Kibana unter dem URL-Pfad “/app/integrations/browse”. Hier sind einige Beispiele:
Der Elastic Agent hat den Vorteil, dass auf einem System nicht mehr mehrere Beats mit redundanten Konfigurations-Dateien eingerichtet werden müssen (z.B. mit Zugangsdaten zum Elasticsearch Cluster).
Da der Elastic Agent noch relativ jung ist, sind zum jetzigen Zeitpunkt noch nicht alle Funktionen der Beats im Elastic Agent enthalten. Dies wird jedoch für die Zukunft angestrebt. Ein offizieller Vergleich der beiden Systeme findet sich hier. Daher müssen die Verantwortlichen im Vorfeld abwägen, welche der beiden Verfahren für ihren Einsatzzweck geeigneter ist, auch ein Parallelbetrieb ist grundsätzlich möglich.
Der Elastic Agent bietet einen weiteren Vorteil gegenüber Beats, denn er lässt sich um den sogenannten Fleet Server erweitern. Der Fleet Server hat die Aufgabe, eine größere Anzahl von Elastic Agents zu verwalten. Dies ist über sogenannte Agent Policies möglich, in denen z.B. festgelegt ist, welche Integrationen auf dem Agent installiert sein sollen. Somit wird die Verwaltung von vielen gleichartigen Systemen (z.B. ein Verbund aus Webservern) stark vereinfacht, da die Konfiguration über eine zentrale Stelle geschieht und anschließend automatisch auf die Server verteilt wird.
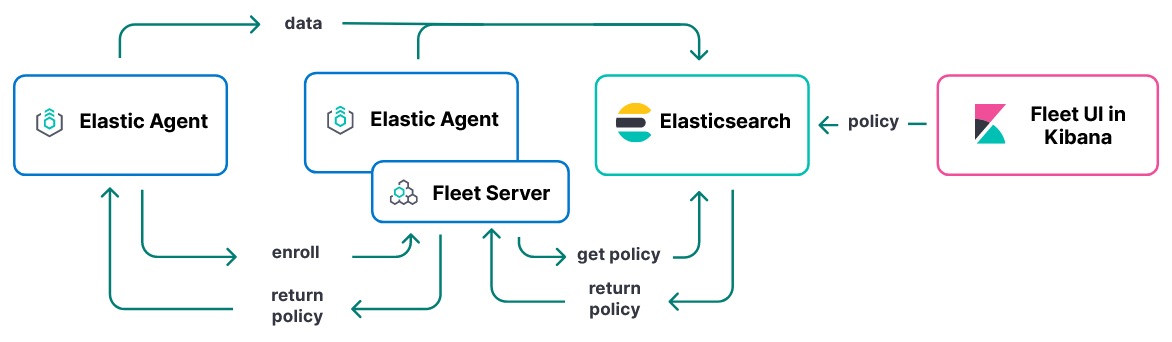
Das obige Schaubild zeigt den Aufbau eines Elastic Clusters mit Elastic Agents und Fleet Server. Zunächst muss der Elastic Agent mit dem Fleet Server verbunden werden, das sogenannte “Enrollment” (links unten zu sehen). Dann wird in Kibana eine Agent Policy über die UI oder die API angelegt. Diese wird in einem Elasticsearch Index gespeichert. Der Fleet Server holt sich die Policy von Elasticsearch und leitet diese an den Elastic Agent weiter, der die nötigen Aktionen ausführt (z.B. bestimmte Integrationen installieren). Anschließend kann der Agent Daten sammeln und an Elasticsearch senden.
Die wichtigsten Tipps für Einsteiger
Die Vielfalt des Elastic-Ökosystems kann für Einsteiger anfangs überwältigend sein. Hier sind einige Tipps, um den Einstieg leichter zu machen:
-
Ein Schritt nach dem anderen: am Anfang ist es wichtig, sich auf das Wesentliche zu konzentrieren. Elasticsearch und Kibana reichen aus, um die ersten Erfolgserlebnisse zu haben, nämlich die Kibana-Weboberfläche zu sehen. Später können weitere Komponenten hinzugefügt und ausprobiert werden, SSL/TLS konfiguriert werden und vieles mehr.
-
Theorie und Praxis: der theoretische Hintergrund ist zwar für das allgemeine Verständnis hilfreich, dennoch spielt Praxiserfahrung eine entscheidende Rolle. Ein schneller Einstieg mit praktischen Übungen ist hilfreich, um ein besseres Gefühl für den Elastic Stack zu bekommen. Dafür können zum Beispiel die folgenden Teile dieser Blogreihe genutzt werden.
-
Alle Arbeitsschritte dokumentieren: es ist sehr wichtig, von Anfang an ein Dokument anzulegen (Textdatei, Markdown, Confluence, …), in dem alle Arbeitsschritte dokumentiert werden. So kann im Anschluss nachvollzogen werden, welche Befehle ausgeführt wurden, welche Ziele verfolgt wurden, welche Aufgaben offen sind und wie ein bestimmter Zustand reproduziert werden kann. Das hilft besonders, wenn man nach einer längeren Pause zum Thema zurückkehrt.
-
Auf öffentliches Wissen zurückgreifen: die offizielle Elastic Dokumentation ist sehr umfangreich und enthält die Antworten auf viele Fragen. Daneben gibt es eine aktive Community, die bei konkreten Problemen hilft. Anlaufstellen dafür sind z.B. das Elastic Forum, StackOverflow und Reddit.
Fazit
Im ersten Teil der Artikelreihe haben wir uns die grundlegenden Komponenten des Elastic Stack sowie erste Anwendungsszenarien angesehen. Der Elastic Stack bietet sowohl Anfängern als auch erfahrenen Anwendern die Möglichkeit, Daten auf innovative Weise zu nutzen und wertvolle Erkenntnisse zu gewinnen. Die kontinuierliche Weiterentwicklung und die aktive Community machen den Elastic Stack zu einem spannenden Bereich der Datenanalyse.
In den nächsten Artikeln der Reihe werden wir uns mit folgenden Themen beschäftigen:
-
Einrichten einer lokalen Elastic-Testumgebung mit Vagrant unter Windows
-
Installation und Konfiguration von Elasticsearch, Kibana, Logstash usw.
-
Debugging von Problemen im Elastic Stack
-
LetsEncrypt Zertifikate automatisch generieren
